by Jan Sodoge
“She took the midnight train going anywhere”… this line by the band Journey (probably not aiming to accurately capture the public transport situation in the USA of the 1980s) leaves a young generation of European long-distance travelers wondering: but why not the bus? Almost 40 years after “Don´t stop believing” aired, long-distance traveling “going anywhere” has been shaped by the rise of the long-distance bus. The data collected and analyzed in this project centers on a comparison of the long-distance bus and train. Holding both a dense bus- and train-network, data is analyzed for the case of Germany to compare data on connections from the major providers i.e. Deutsche Bahn (the main German train company) and Flixbus (as an internationally operating company). Based on a set of popular travel routes between cities, data is crawled on the respective websites of the scheduled bus- and train-connections. Then, we compare the quantity, prices and duration of connections.
Duration
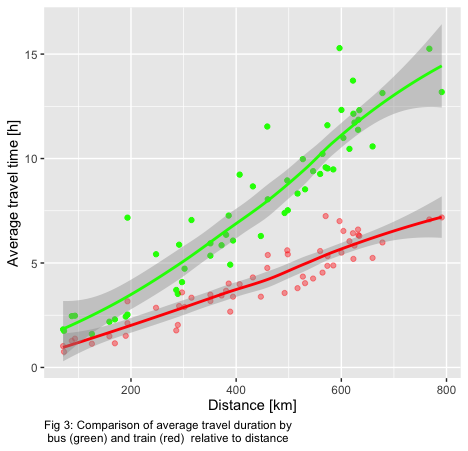
Using the derived dataset, a comparison of traveling with both types of vehicles, not only with regard to small-town girl and small-town boy becomes feasible. I assume duration, price and time of departure as crucial decision-making parameters to choose between “train [or bus] going anywhere” and thus relevant for this analysis. Concerning travel duration, I find most connections to consume more time if traveled with by bus. Time differences grow larger with longer journeys as shown in Fig. 2. Also, a higher standard deviation of travel times by bus compared to trains is exemplified.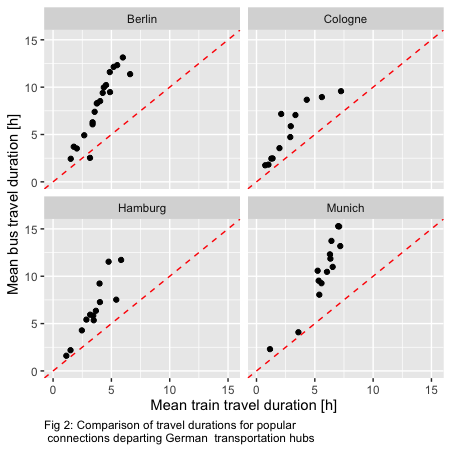
Prices
Concerning the price-levels, there is a crucial differentiation to be made for train-based traveling. Saver’s price offers are priced dynamically and cheaper if booked early in advance (the saver’s prices were scraped 16 days in advance of travel) whereas normal train prices are fixed. Fig. 4 visualizes the relation of prices in relation to the spatial distance of the particular connection. Similar to travel durations, I find an increasing difference in prices along with increasing traveling distances.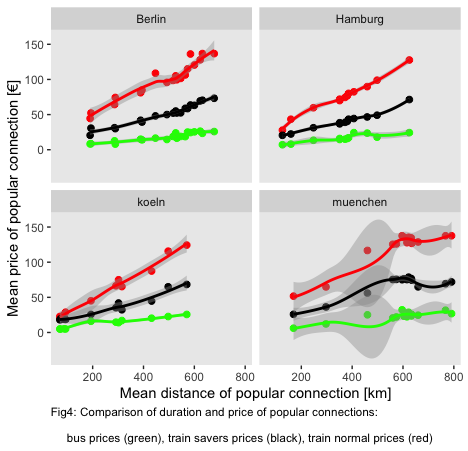
The midnight option
Coming back to the pop-cultural reasoning to this investigation: what about the midnight-train home? Fig. 7 shows the relatives shares both for bus and train connections per hour of the day. The majority of train connections analyzed departs between 7am and 17pm. For the evening and night hours though, a significantly larger share of bus connections is departing.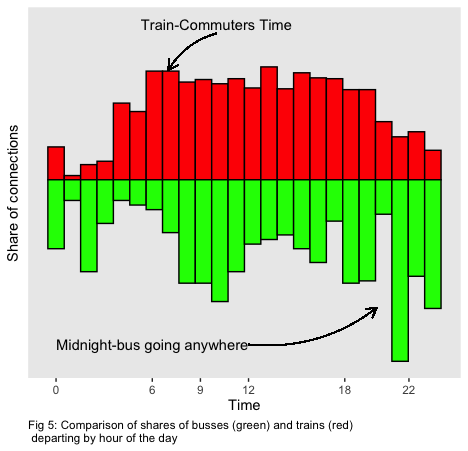
This piece was originally published as an assignment within the Computational Social Science Master Program at the Institute for Analytical Sociology, Linköping University, Sweden.
To enable similar projects based on this type of data, and push transparency of this work, the following
sections describes the process by which the data was collected. Also, the code for scraping and analysis is
made publicly available here.
The data collection process is three folded. First, data from the Flixbus website is used to generate a
network-structure of cities and popular connections between these. Within the second and third steps,
data on scheduled connections for these popular connections are collected.
1. Representing the network nodes, a list of all German cities holding a Flixbus station is scraped
(also holding georeferenced locations). I adapt a Flixbus-internal ID for each city as an identifier.
The list is merged with data on population sizes of cities from Wikipedia. The edges in the network-structure
are represented by “popular connections” (defined by departure- and arrival-city) according to Flixbus. These
are documented on a city-profile page on the Flixbus website describing above-average booked connections from
or to that particular city. On average, 35 popular connections are listed per city. A first step, necessary to
reduce the computational workload for the remaining process, the network-structure is reduced to cities (and
connections between cities) with more than 80.000 citizens.
2. The 6.5.2020 is selected as the date for which scheduled connections are scraped. To ensure comparability,
for both bus and train information on arrival- and departure time, duration, prices, number of changes required,
and connected waiting time is collected. Collecting these data from Flixbus.com, the functioning of the
search-function needs to be taken into account. If there is no particular connection matching the search
conditions (i.e. departure and arrival location and date), the website suggests connections with slightly
different cities or a later date. I term these connections “secondary”, whereas the “primary” connections
describe these matching the exact locations for departure and arrival city and date. The dataset for bus
connections contains all realized connections between cities with more than 80.000 citizens. 3. To collect
data on train connections, Bahn.de is crawled using Selenium to expand the table displaying connections).
No differentiation between primary and secondary connections is needed. As the application of Selenium is
computationally intensive and unstable, the set of crawled connections is reduced to those leaving the cities
Hamburg, Cologne, Munich, and Berlin (four largest cities and major transportation hubs) and arriving in cities
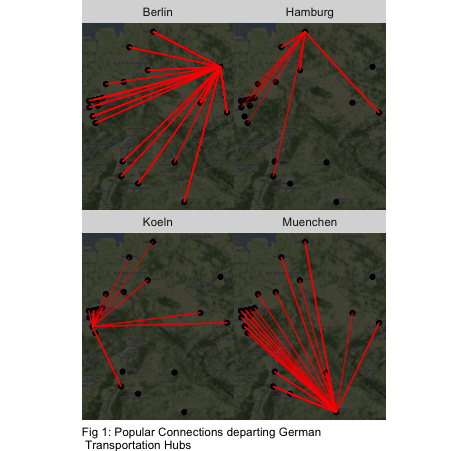
with more than 300.000 citizens (see Fig. 1). For the comparison between train and bus, the dataset on bus
connections is consequently reduced to the same extent of popular connections (also limiting to only primary
connections). To enhance analysis, the Google Distance Matrix API is used to generate data on the spatial
distance between departure- and arrival-city for each connection.